
En este post, definiremos los conceptos de Data Warehouse y Data Marts, revisando los esquemas de diseño de Copo de Nieve, Estrella e Híbrido.
¿Qué es un Data Warehouse y por qué se caracteriza?
Un Data Warehouse es una base de datos corporativa en la que se integra información depurada de las diversas fuentes que hay en la organización. Dicha información debe ser homogénea y fiable, se almacena de forma que permita su análisis desde muy diversas perspectivas, y que a su vez dé unos tiempos de respuesta óptimos. Para ello la información se encuentra altamente desnormalizada y modelada de una forma bastante diferente a los sistemas transaccionales, principalmente se utilizan los modelos en estrella (star schema) y en copo de nieve (snowflake schema) que estudiaremos más adelante.
Un Data Warehouse es mucho más que lo que hemos comentado hasta el momento. Según Bill Inmon se caracteriza por ser:
- Orientado a temas: los datos están organizados por temas para facilitar el entendimiento por parte de los usuarios, de forma que todos los datos relativos a un mismo elemento de la vida real queden unidos entre sí. Por ejemplo, todos los datos de un cliente pueden estar consolidados en una misma tabla, todos los datos de los productos en otra, y así sucesivamente.
- Integrado: los datos se deben integrar en una estructura consistente, debiendo eliminarse las inconsistencias existentes entre los diversos sistemas operacionales. La información se estructura en diversos niveles de detalle para adecuarse a las necesidades de consulta de los usuarios. Algunas de las inconsistencias más comunes que nos solemos encontrar son: en nomenclatura, en unidades de medida, en formatos de fechas, múltiples tablas con información similar (por ejemplo, tener varias aplicaciones en la empresa, cada una de ellas con tablas de clientes).
- Histórico (variante en el tiempo): los datos, que pueden ir variando a lo largo del tiempo, deben quedar reflejados de forma que al ser consultados reflejen estos cambios y no se altere la realidad que había en el momento en que se almacenaron, evitando así la problemática que ocurre en los sistemas operacionales, que reflejan solamente el estado de la actividad de negocio presente. Un Data Warehouse debe almacenar los diferentes valores que toma una variable a lo largo del tiempo. Por ejemplo, si un cliente ha vivido en tres ciudades diferentes, debe almacenar el periodo que vivió en cada una de ellas y asociar los hechos (ventas, devoluciones, incidencias, etc.) que se produjeron en cada momento a la ciudad en la que vivía cuando se produjeron, y no asociar todos los hechos históricos a la ciudad en la que vive actualmente. Si un cliente, durante todo el tiempo en que le hemos estado vendiendo ha pasado por tres estados civiles (soltero, casado y divorciado) debemos saber qué estado civil tenía en el momento en que le realizamos cada una de las ventas.
- No volátil: la información de un Data Warehouse, una vez introducida, debe ser de sólo lectura, nunca se modifica ni se elimina, y ha de ser permanente y mantenerse para futuras consultas. Por ejemplo, si en el origen se modifica la cantidad de un producto que entra en el almacén, en el Data Warehouse no podemos hacer directamente una actualización sobre ese registro sin dejar ni el más mínimo rastro de que hubo antes otro valor.
Adicionalmente estos almacenes contienen metadatos (datos sobre los datos), que aportan un valor adicional, permitiendo tener información sobre su procedencia (sobre todo cuando tenemos múltiples fuentes), la periodicidad con la que han sido introducidos, la fiabilidad que nos ofrecen, etc. Todo ello nos aporta una ayuda adicional, tanto al usuario final como a los técnicos responsables de su mantenimiento, ayudando a estos últimos en aspectos como su auditoría y administración.
Entonces... ¿Qué es un Data Marts?
Kimball determinó que para él un Data Warehouse no era más que un conjunto de los Data Marts de una organización. Un Data Mart es una copia de las transacciones específicamente estructurada para la consulta y el análisis. Defiende por tanto una metodología Bottom-up a la hora de diseñar un almacen de datos.
Según Ralph Kimball, “Un Data Mart es un conjunto de datos flexible, idealmente basado en el nivel de granularidad mayor que sea posible, presentado en un modelo dimensional que es capaz de comportarse bien ante cualquier consulta del usuario. En su definición más sencilla, un data mart representa un único proceso de negocio”.
Un proceso de negocio es un conjunto de tareas relacionadas lógicamente llevadas a cabo para lograr un resultado de negocio definido. La norma internacional ISO-9001 define un proceso como “una actividad que utiliza recursos, y que se gestiona con el fin de permitir que los elementos de entrada se transformen en resultados”.
Diferencias entre DataWarehouse vs Data Marts
La diferencia de Data Warehouse y Data Marts es solamente en cuanto al alcance. Mientras que un Data Warehouse es un sistema centralizado con datos globales de la empresa y de todos sus procesos operacionales, un Data Mart es un subconjunto temático de datos, orientado a un proceso o un área de negocio específica. Debe tener una estructura óptima desde todas las perspectivas que afecten a los procesos de dicha área. Es más, según Ralph Kimball, cada Data Mart debe estar orientado a un proceso determinado dentro de la organización, por ejemplo, a pedidos de clientes, a compras, a inventario de almacén, a envío de materiales, etc.
Si optamos por una solución basada en Data Marts, hay algo muy importante a tener en cuenta, no podemos volver a generar islas de información de las diferentes áreas o procesos de negocio, sino que han de quedar totalmente integradas para poder obtener siempre información coherente de toda organización. Para ello nos apoyamos en el uso de un Bus Dimensional.
Un Bus Dimensional es un esquema, habitualmente en forma de tabla, que representa los diversos Data Marts y las diferentes dimensiones definidas en nuestra organización. Como lo habitual es que se vayan creando en diversas fases, también se puede añadir una columna para representar en qué fase se abordará cada Data Mart. A continuación mostramos un ejemplo:
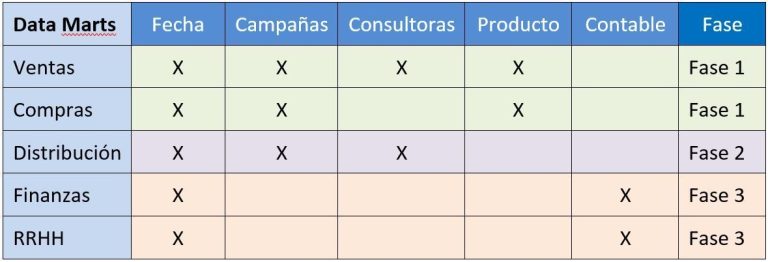
Nota: La existencia de un Data Warehouse no descarta la existencia de Data Marts, ni viceversa. Es decir, puede haber organizaciones que tengan sólo un Data Warehouse, que sólo tengan Data Marts, o que tengan un Data Warehouse y Data Marts.
Cursos de Data, Analítica de Datos e IA
Modelado Dimensional: Esquema en Estrella y en Copo de nieve (snowflake schema)
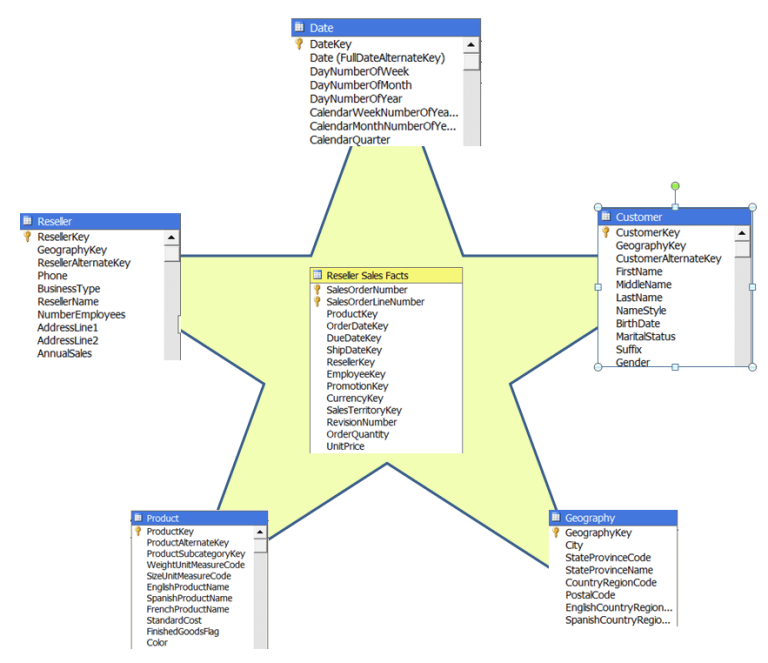
A la hora de modelar el Data Mart o Data Warehouse, hay que decidir cuál es el esquema más apropiado para obtener los resultados que queremos conseguir. Habitualmente, y salvo excepciones, se suele modelar la base de datos utilizando el esquema en estrella (star schema), en el que hay una única tabla central, la tabla de hechos, que contiene todas las medidas y una tabla adicional por cada una de las perspectivas desde las que queremos analizar dicha información, es decir por cada una de las dimensiones:
La otra alternativa de modelado es la utilización del esquema en copo de nieve (snowflake schema). Esta es una estructura más compleja que el esquema en estrella. La diferencia es que algunas de las dimensiones no están relacionadas directamente con la tabla de hechos, sino que se relacionan con ella a través de otras dimensiones. En este caso también tenemos una tabla de hechos, situada en el centro, que contiene todas las medidas y una o varias tablas adicionales, con un mayor nivel de normalización (ver imagen):
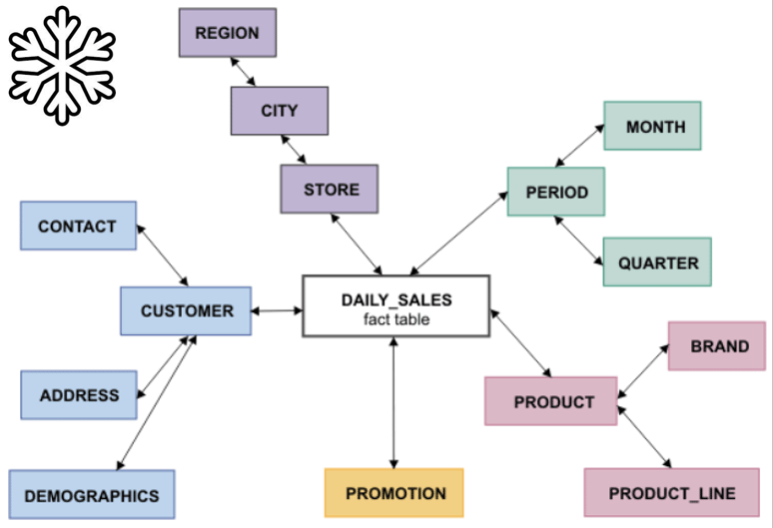
El modelo en estrella, aunque ocupa más espacio en disco (dato cada vez menos significativo), es más simple de entender por el usuario y ofrece un mejor rendimiento a la hora de ser consultado.
En ocasiones se opta por un modelo híbrido, que tiene parte en estrella y parte en copo de nieve.
Veamos un ejemplo de un esquema en el que hemos utilizado un modelo híbrido:
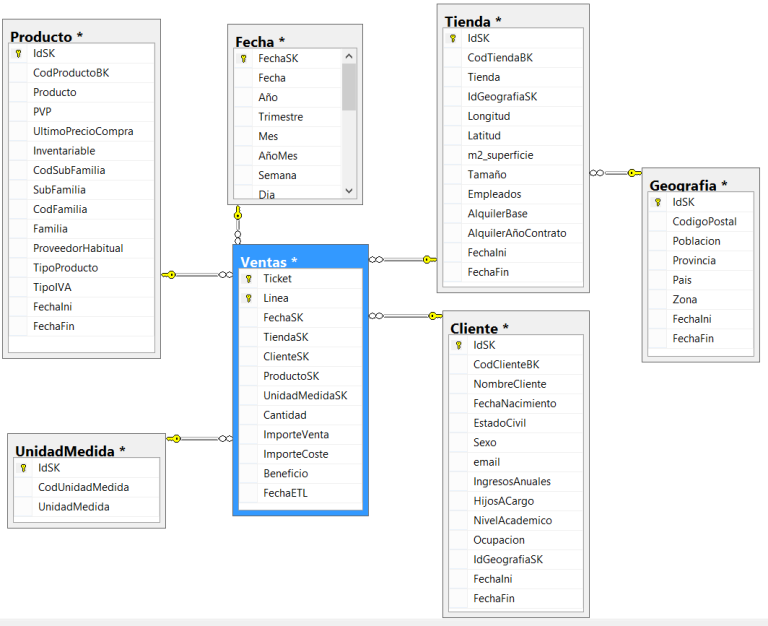
Este modelo que aparece en la imagen anterior, es un modelo que utilizamos frecuentemente en Verne Academy para mostrar diversos análisis Comerciales y de Ventas, concretamente pertenece al caso práctico “Ventas en cadena Tiendas 24H”. En él hemos modelado la dimensión Geografía en copo de nieve (snowflake) con el fin de poder reutilizarla desde diversas dimensiones (tiendas, proveedores, clientes, empleados, etc.) que habitualmente tienen datos geográficos.







